Best Practices for Ensuring Service Availability with AWS ALB
In an AWS EKS environment, using an ALB may lead to service downtime. The issue typically arises as follows:
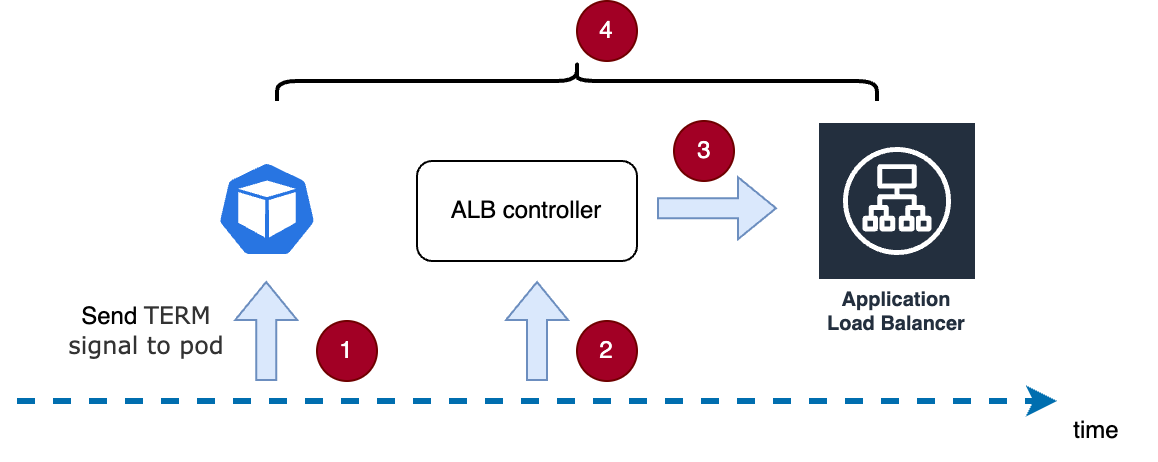
Time Point 1: When Kubernetes decides to terminate a pod, it sends a TERM signal. The pod may stop immediately or after completing all inflight requests, at which point its status is marked as Terminating.
Time Point 2: The ALB (Application Load Balancer) controller detects that the pod's status is Terminating and attempts to remove the pod's IP from the ALB.
Time Point 3: The ALB controller calls the appropriate API to remove the pod's IP from the ALB.
During this process, if any new requests arrive at the pod during Time Period 4, those requests will fail. This is a common issue, as highlighted in a related GitHub issue.
Key Insight: The TERM signal should only be sent after the pod's IP has been removed from the ALB.
Proposed Solution: While this solution may not be perfect, it is a recommended practice. By using a preStop lifecycle hook in the deployment, the TERM signal can be delayed by 5 seconds, allowing sufficient time for the operations at Time Points 2 and 3 to complete.
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: game-2048
name: deployment-2048
spec:
selector:
matchLabels:
app.kubernetes.io/name: app-2048
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/name: app-2048
spec:
containers:
- image: public.ecr.aws/l6m2t8p7/docker-2048:latest
imagePullPolicy: Always
name: app-2048
ports:
- containerPort: 80
lifecycle:
preStop:
exec:
command: ["/bin/sh","-c","sleep 5"]