AutoscalingPolicy
AutoscalingPolicy defines which Workloads should have their Requests and Limits automatically adjusted, when these adjustments should occur, and how they should be applied. By properly configuring an AutoscalingPolicy, you can continuously adjust the Requests of a group of Workloads to a reasonable and efficient level.
Note: If a Pod contains sidecar containers (e.g., Istio), we won’t modify them, and they will be excluded from recommendation calculations. We detect sidecars by diffing the container names between the workload’s Pod template and the actual Pod; any names that exist only in the Pod are treated as injected sidecars.
Enable*
Enable toggles whether an AutoscalingPolicy is active (enabled by default).
When set to Disabled, the policy is removed from the cluster and retained only on the server. This operation effectively deletes the AutoscalingPolicy and will trigger the On Policy Removal actions.
Priority
When multiple AutoscalingPolicies match the same Workload, Priority determines which policy takes precedence.
- An AutoscalingPolicy with a higher Priority value will be applied first.
- If two AutoscalingPolicies have the same Priority, the one created earlier will be applied.

The Priority field allows you to flexibly apply AutoscalingPolicies across your workloads.
For example:
- You can configure an AutoscalingPolicy with Priority = 0 that matches most or even all Workloads but does not actively adjust them.
- Then, you can define additional AutoscalingPolicies with higher Priority values to target specific Workloads with more aggressive adjustment strategies.
Recommendation Policy Name*
The RecommendationPolicyName specifies which Recommendation Policy the AutoscalingPolicy should use to calculate recommendations. It defines both the calculation method and the applicable scope.
For details, see Recommendation Policy.
TargetRefs
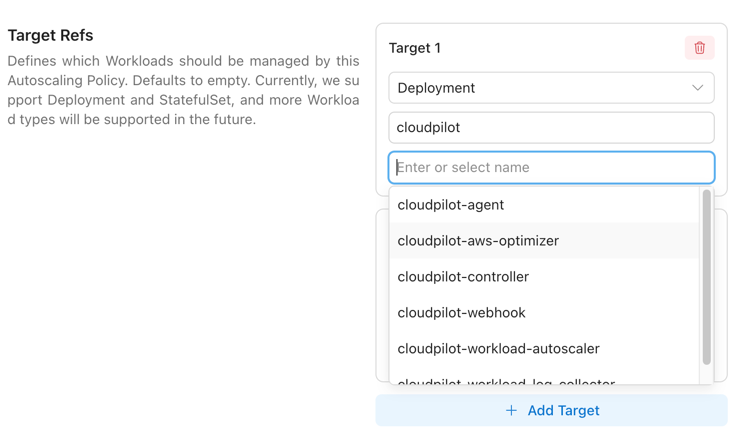
TargetRefs specify the scope of Workloads to which the AutoscalingPolicy applies. You can configure multiple TargetRefs to cover a broader set of Workloads.
| Field | Allowed Values | Required | Description |
|---|---|---|---|
| Kind | Deployment | StatefulSet | DaemonSet | Yes | Type of Workload. Currently supports Deployment, StatefulSet, and DaemonSet. |
| Name | Any valid Workload name | empty | No | Name of the Workload. If left empty, it matches all Workloads within the namespace or cluster (depending on Namespace). |
| Namespace | Any valid namespace | empty | No | Namespace of the Workload. If left empty, it matches all namespaces in the cluster. |
| LabelSelector | Kubernetes label selector (matchLabels + matchExpressions) | No | Additional label-based filtering for matched Workloads. |
Name and Namespace support shell-style glob patterns (*, ?, and character classes like [a-z]); patterns match the entire value, and an empty field (or *) matches all.
DaemonSet recommendation: When a policy targets
DaemonSet, prefer OnCreate and InPlace for normal optimization. Use ReCreate only after you have verified that restarting the DaemonSet Pods will not disrupt node-local services, networking, security agents, or other infrastructure functions.
| Pattern | Meaning | Matches | Doesn’t match |
|---|---|---|---|
* | Any value | web, ns-1, default | — |
web-* | Values starting with web- | web-1, web-prod-a | api-web-1 |
*-prod | Values ending with -prod | core-prod, a-prod | prod-core |
front? | front + exactly 1 char | front1, fronta | front10, front |
job-?? | job- + exactly 2 chars | job-01, job-ab | job-1, job-001 |
ns-[0-9][0-9]-* | ns- + two digits + - + anything | ns-01-a, ns-99-x | ns-1-a |
db[0-2] | db0, db1, or db2 only | db0, db2 | db3, db-2 |
[^0-9]* | Does not start with a digit | app1, ns-x | 9-app |
LabelSelector
LabelSelector is used to further filter matched Workloads by label. Both matchLabels and matchExpressions are supported.
After a workload is selected, Workload Autoscaler still resolves the actual Pods through controller ownership. This keeps blue/green or canary rollouts with shared labels from accidentally mixing sibling workloads.
Each item in matchExpressions contains:
| Field | Description |
|---|---|
key | The label key to match |
operator | The selector operator |
values | The list of values used by the operator. Required for In and NotIn |
Available operators:
| Operator | Description |
|---|---|
In | Matches when the label value is in values |
NotIn | Matches when the label value is not in values |
Exists | Matches when the label key exists |
DoesNotExist | Matches when the label key does not exist |
CloudPilot AI labels identified Java workloads with evpa.cloudpilot.ai/primary-runtime-language: java.
Example: match Java workloads
Use key: evpa.cloudpilot.ai/primary-runtime-language, operator: In, and values: [java].
Update Schedule
UpdateSchedule defines when a Workload should use a particular update mode.
- Items listed later in the schedule have higher priority.
- If no schedule matches, the default mode is
Off.
By configuring multiple Update Schedule Items, you can apply different update modes at different times. For example:
- During the day, only allow updates using the
OnCreatemode. - At night, allow updates using the
ReCreatemode.
Update Schedule Item
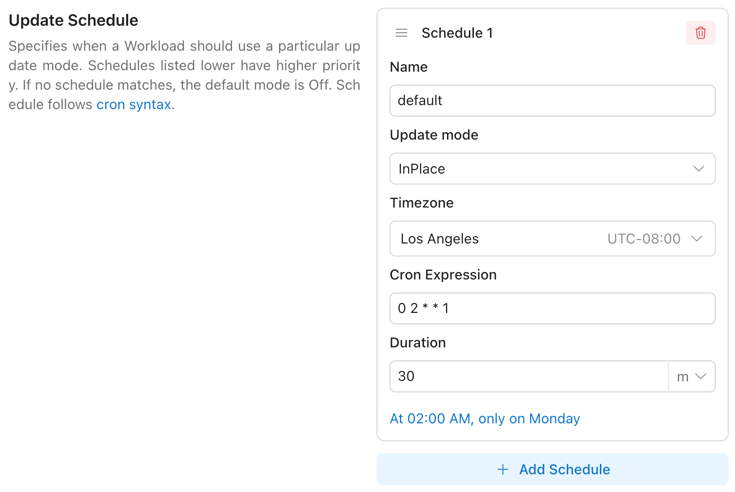
| Field | Allowed Values / Format | Description |
|---|---|---|
Name | Any non-empty string | Human-readable name of this schedule item. |
Cron Expression | Cron expression (e.g., 0 2 * * *) | Start time defined by a cron schedule. Must follow standard cron syntax. Must be provided together with Duration. |
Duration | Go/K8s duration string (e.g., 30m, 1h) | Length of time the Update Mode remains active after Cron Expression triggers. Must be provided together with Cron Expression. |
Update Mode | OnCreate | ReCreate | InPlace | Off | Update behavior to apply when this item is active. |
Timezone | IANA Time Zone name | Time zone for interpreting the Cron Expression field. Defaults to UTC if not specified. |
Constraint: Cron Expression and Duration are jointly optional — either both present (time-windowed rule) or both absent (always applicable rule with the specified mode).
You can visit here to refer to how the Cron syntax of the Cron Expression field works.

UpdateMode
| Value | Behavior | Typical Use Case |
|---|---|---|
OnCreate | Apply normal recommendations only when new Pods are created. | No proactive restart for ordinary recommendation changes. |
ReCreate | Apply changes by recreating Pods (rolling replace). | When in-place vertical changes are not supported or a clean restart is desired. |
InPlace | Apply changes in place to running Pods (no recreate). | Minimal disruption on clusters that support in-place resource updates. |
Off | Do not apply changes (disabled). | Temporarily pause updates. |
DaemonSet recommendation: For
DaemonSet, we recommend OnCreate as the safest baseline and InPlace when your cluster supports it and the workload tolerates in-place resource updates. Choose ReCreate only when you have confirmed that proactively restarting DaemonSet Pods will not affect service continuity on each node.
OnCreate Admission Mutation

OnCreate is implemented by the Pod mutating admission webhook. Instead of changing an existing Pod, it mutates a newly created Pod before it is persisted by the Kubernetes API server.
OOM recovery exception: The recommender and
OnCreateadmission path do not restart existing Pods for ordinary recommendation changes. While an active OOM boost exists, however, the separate OOM Recovery controller may evict an OOM Pod that is still below the boost floor or trigger an eligible single-replica Deployment rollout. The replacement Pod then receives the boost through admission. This safety path means anOnCreateworkload can be replaced after OOM without changing the behavior of normal recommendations.
A Pod is eligible for admission-time mutation only when all of the following are true:
| Gate | Required state | What happens if it is not satisfied |
|---|---|---|
| Workload mapping | The Pod belongs to a supported workload with an existing AutoscalingPolicyConfiguration (APC). | The Pod is admitted unchanged. |
| APC lifecycle | The APC is not being deleted. | The Pod is admitted unchanged. |
| Update mode | APC status.updateMode is OnCreate, ReCreate, or InPlace. | The Pod is admitted unchanged. |
| Proactive update switch | The workload does not set evpa.cloudpilot.ai/disable-proactive-update: "true". | Resource mutation is skipped. |
| Initial onboarding gate | For newly managed Deployment, StatefulSet, and DaemonSet workloads, the APC has already latched the first successful metrics window (status.initialOptimizationDataWindowSatisfiedAt), or the controller-level gate is disabled. | The Pod is admitted unchanged. While this gate is pending, neither normal recommendations nor OOM boost mutations are applied. |
| Recommendation or OOM boost | RecommendationReady=True or the APC has an active OOM boost. | Resource requests are not changed; default resize policies and Java heap env integration may still be ensured. |
When the Pod is eligible, the webhook stages all container changes first and applies them only if every staged change succeeds. This all-or-nothing behavior prevents partially mutated Pods. Containers that are not part of the workload template, such as injected sidecars, are left unchanged.
For each workload container, the webhook uses a recommendation baseline only when that recommendation is safe and current for the admission decision. Otherwise, it starts from the APC’s status.originalRequests. It then overlays any active OOM boost on the selected baseline. Therefore, if the RecommendationPolicy has changed but the APC still contains recommendations from the old policy hash, stale recommendations are not applied; an active OOM boost can still be overlaid on originalRequests while fresh recommendations are pending.
When the UpdateMode is set to either ReCreate or InPlace, the OnCreate mode will also be applied automatically. This ensures that when a Pod restarts normally, the newly created Pod will always receive the latest recommendations, regardless of the Drift Thresholds.
Tip: You can disable all optimization actions for a specific workload by adding the annotation
evpa.cloudpilot.ai/disable-proactive-update: "true"to the workload. This disables proactive updates, evictions, and OnCreate mutations. For more details, see Workload Configuration.
For ReCreate operations, when attempting to evict a single-replica Deployment without PVCs, we perform a rolling update to avoid service interruption during the update.
Note: The
InPlacemode has certain limitations and may automatically fall back toReCreatein some cases. For details, see InPlace Limitations.
Update Safety Behaviors
The Workload Autoscaler includes several built-in safety behaviors during proactive updates:
- Workload readiness check: The controller only applies updates when the target workload is in a Ready state. If the workload is not ready (e.g., during a rollout), updates are skipped until it stabilizes.
- Newest Pod first: When multiple Pods in a workload are drifted, the newest Pod is updated first. Pods that are being deleted, preempted, or stuck in scheduling are always skipped.
- RecommendationPolicy hash consistency: If the
RecommendationPolicyspec has changed but the Recommender has not yet recalculated recommendations with the new spec, proactive updates are paused to avoid applying stale recommendations. Updates resume automatically after the next successful recommendation cycle. - APC replacement isolation: If an
AutoscalingPolicyConfigurationis deleted and recreated with the same namespace and name, the replacement is treated as a new Kubernetes object. It does not inherit the previous object’s recommendation cooldown or in-progress scheduling state. WhileRecommendationReadyis missing orFalse, recommendation attempts use a 90-second retry interval; after it becomesTrue, the configuredRecommendationPolicyevaluation period applies. - Initial onboarding data window: For newly managed
Deployment,StatefulSet, andDaemonSetworkloads, proactive updates stay paused until the first configured metrics window is satisfied. The first pass is evaluated from workload-level history rather than a single Pod lifetime, and the gate is latched bystatus.initialOptimizationDataWindowSatisfiedAt, so later rollouts or short-lived metric gaps do not reopen it. - Startup Boost awareness: Pods that are within the configured Startup Boost window (based on
MinBoostDurationandMinReadyDuration) are skipped for proactive updates. Once the window expires, a dedicated Boost Reversion step automatically restores resources to the normal recommendations before regular proactive updates run.
Update Resources*

UpdateResources defines which resources should be managed by the Workload Autoscaler.
Available resources: CPU / Memory.
- If this field is omitted, the API defaults it to both
CPUandMemory. An explicitly empty list means that no resources are actively managed. - Only the selected resources will be actively updated.
- This setting does not affect how recommendations are calculated.
If you don’t have specific requirements or if you already use HPA, we recommend allowing both CPU and Memory to be managed.
Note: When you modify the
Update Resources, an update operation may be triggered based on the deviation between the recommended value and the current value. This operation will take effect immediately once the conditions of theUpdate Scheduleare met.
Drift Thresholds

DriftThresholds define the deviation between the recommended value and the current value that should trigger an active update.
- You can configure this as either a percentage or an absolute value.
- The default is 10%.
| Resource Type | Percentage | Absolute Value (Option 1) | Absolute Value (Option 2) |
|---|---|---|---|
| CPU | 20% | 0.5 | 200m |
| Memory | 10% | 0.25Gi | 500Mi |
If the deviation for any resource in a Pod exceeds the threshold, the Pod will be actively updated.
Drift detection checks both Requests and Limits for each resource:
- For managed resources (listed in
UpdateResources): current Requests and Limits are compared against the recommended values. - For unmanaged resources (not in
UpdateResources): current Requests and Limits are compared against the original values recorded before any recommendations were applied.
If either the Request or the Limit for any resource exceeds the threshold, the Pod is considered drifted.
Note: When using a percentage threshold, drift is calculated as
|current - recommended| / current. A threshold of10%means the Pod is drifted when the current value differs from the recommended value by at least 10% of the current value.

On Policy Removal
OnPolicyRemoval defines how Pods are rolled back when an AutoscalingPolicy is removed.
- The default is
Off: the configuration will be deleted, but no action will be taken on existing Pods.

| Value | Behavior on policy removal | Business impact | Recommended scenarios | Notes |
|---|---|---|---|---|
Off | Delete the EVPAC configuration only; do not roll back Pod requests (status quo). | No restart, zero downtime | When rollback is not required; keep current resource settings after troubleshooting. | Limits are unchanged. This option makes no changes to requests/limits. |
ReCreate | Roll back to the pre-policy requests by recreating target Workloads (rolling replace). | Restarts, brief downtime | Cluster does not support in-place vertical changes; require scheduler to reassign resources. | Ensure safe rolling strategy. Limits typically remain unchanged unless your controller handles them. |
InPlace | Roll back to the pre-policy requests via in-place Pod updates (no recreate). | Usually zero/low disruption | Cluster supports in-place vertical resizing; prioritize minimal disturbance. | Requires cluster/runtime support for in-place updates. Limits unchanged unless otherwise implemented. |
For ReCreate operations, when attempting to evict a single-replica Deployment without PVCs, we perform a rolling update to avoid service interruption during the update.
Note: The
InPlacemode has certain limitations and may automatically fall back toReCreatein some cases. For details, see InPlace Limitations. When unexpected situations prevent us from restoring the Pod Request for 10 minutes, we will allow the configuration to be deleted directly without restoring the Pod Request.
Limit Policies

Limit Policies let you control how CloudPilot AI manages CPU/Memory Limits for a workload.
In most cases, we recommend Remove so workloads (especially CPU resource) are not artificially capped and can burst when needed. Workload Autoscaler focuses on keeping Requests accurate; therefore, Limits configuration typically has limited impact on stability—unless you rely on Limits as a hard safety boundary.
Policy Behaviors
| Policy | Behavior |
|---|---|
Remove | Removes Pod limits (no CPU/Memory caps). |
Keep | Keeps existing Pod limits unchanged. |
Multiplier | Recalculates limits by multiplying the recommended Requests by a configured multiplier. |
Auto | Same as Multiplier, but only applies the update when the new Limits are higher than the current/original Limits, ensuring Limits never become lower than the default configuration. If no existing Limit is set for the resource, the controller keeps it unlimited (no Limit is added). |

When changes take effect
Updating the Limit Policy may trigger a rollout/update. The decision depends on:
- how far the current values deviate from the recommended values, and
- whether existing Pods match the expected limits configuration.
Once the configured Update Schedule conditions are met, changes are applied immediately.
Operational guidance
When using Multiplier / Auto, we strongly recommend setting a reasonable lower bound for CPU/Memory recommendations. In rare cases (e.g., test environments with extremely low observed usage), recommendations may be too small to support stable startup or sudden traffic spikes.
Note: With
Keep, the final recommended Requests will be clamped so they never exceed your configured Limits. This means the recommendation may be lower than what the algorithm calculates if the current Limit is below the recommended value. If you want Pods to burst beyond current caps when needed, considerRemoveorMultiplier.
InPlace Fallback
InPlace updates can fail for various reasons — for example, insufficient node resources (PodResizePending), QoS class conflicts, or JVM Heap env var changes that require a container restart. When this happens, the Workload Autoscaler needs a fallback strategy to decide whether to recreate the Pod or hold and wait.
InPlaceFallback lets you configure this behavior per failure reason. You can set a global default policy and override it for specific reasons.
| Field | Type | Description |
|---|---|---|
defaultPolicy | InPlaceFallbackPolicy | Default fallback policy used when no reason-specific rule is set. Defaults to recreate in general, but for DaemonSet we recommend hold. |
reasonPolicies | map[InPlaceFallbackReason]InPlaceFallbackPolicy | Override policy for specific failure reasons. Key must be a valid InPlaceFallbackReason. |
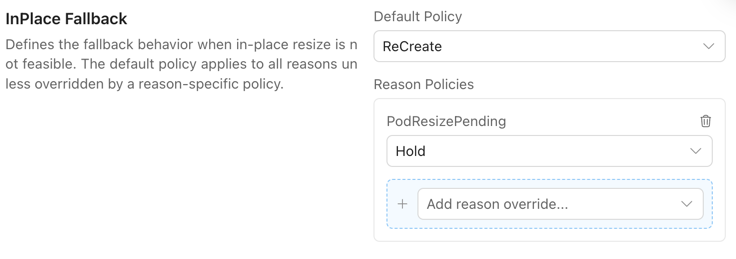

Supported InPlaceFallbackPolicy values:
| Value | Behavior |
|---|---|
recreate | Fall back to recreate-based update. |
hold | Keep current Pod unchanged and wait for manual intervention or future retry conditions. |
DaemonSet recommendation: For
DaemonSet, prefer hold as the fallback policy. This avoids immediately recreating a DaemonSet Pod after an in-place resize failure. Use recreate only when you have explicitly confirmed that an additional restart is acceptable for that DaemonSet.
Supported InPlaceFallbackReason values:
PodResizePendingQoSChangeForbiddenMemoryLimitsAddForbiddenResourceLimitsRemoveForbiddenResourceRequestsRemoveForbiddenResourceMemoryLimitCannotBeDecreasedJVMHeapDrift
If a failure reason is not listed in reasonPolicies, the controller uses defaultPolicy.
ResourceStartupBoost

ResourceStartupBoost allows you to apply a temporary resource boost during workload startup. This is designed for workloads that require significantly more resources at startup than at steady state (e.g., the Java startup spike).
Fields
| Field | Allowed Values / Format | Description |
|---|---|---|
Enabled | Bool | Enables or disables ResourceStartupBoost. |
Min Boost | Time Duration | Minimum duration that Startup Boost remains active per Pod. |
Min Ready | Time Duration | Minimum time a Pod must stay in Ready state before resources can be restored. |
CPU Resource Multiplier | [1, 5] | Multiplier applied to the recommended CPU Requests and Limits during Boost. |
Memory Resource Multiplier | [1, 5] | Multiplier applied to the recommended Memory Requests only during Boost (Limits are not increased — see below). |

Memory boost behavior (InPlace Update limitation)
Due to InPlace Update limitations, when boosting Memory, CloudPilot AI will increase Requests only, and will not increase Limits. After boosting, the boosted Requests value will never exceed the configured Limits.
CPU boost is applied to both CPU Requests and CPU Limits when the corresponding fields exist. Memory boost is intentionally applied only to Memory Requests because Kubernetes does not allow decreasing a Pod’s Memory Limit in place. Keeping the Limit unchanged avoids creating a boosted Limit that cannot be safely reverted later.
Pod annotations and lifecycle
When a Pod is boosted at admission time, it is annotated with evpa.cloudpilot.ai/startup-boosted: "true". The Pod remains in the boost window until both conditions are satisfied:
- the Pod has existed for at least
Min Boost, and - the Pod has stayed
Readyfor at leastMin Ready.
During this window, regular proactive updates and OOM recovery skip the Pod so the startup protection is not interrupted. After a successful reversion, the annotation changes to evpa.cloudpilot.ai/startup-boosted: "reverted", which prevents the same Pod from being processed again.
Boost Reversion
Once the boost window expires (both Min Boost and Min Ready conditions are satisfied), CloudPilot AI automatically reverts the Pod’s resources to the normal recommended values via InPlace resize.
The reversion process operates independently of the following conditions, ensuring boosted resources are always cleaned up:
- UpdateMode — reversion runs regardless of the current update mode (
InPlace,ReCreate,OnCreate, orOff). - Drift Thresholds — reversion does not depend on whether the boosted resources exceed the configured drift threshold.
- Workload Readiness — reversion checks individual Pods rather than overall workload readiness.
- JVM Heap Drift — since startup boost only affects resource Requests/Limits and has no impact on JVM heap settings, reversion proceeds independently of heap drift status.
If the InPlace revert fails (e.g., insufficient node resources), the Pod is marked with InPlaceResizeFailed and handled by the standard InPlace Fallback mechanism.
After a successful reversion, the Pod’s startup-boosted annotation is updated from "true" to "reverted" to prevent repeated processing.

Requirements
To use ResourceStartupBoost:
- Kubernetes version must be v1.33+
DisableRuntimeOptimization
DisableRuntimeOptimization allows you to turn off all runtime-specific optimizations for workloads managed by an AutoscalingPolicy. When enabled, workloads are treated as generic workloads regardless of detected runtime language.
| Field | Allowed Values | Default | Description |
|---|---|---|---|
DisableRuntimeOptimization | Bool | false | When set to true, all runtime-specific optimizations are disabled for workloads managed by this policy. |
What Changes When Disabled
When DisableRuntimeOptimization is set to true:
- Memory recommendations use generic percentile-based calculations instead of JVM-aware algorithms (GC pressure, heap wave analysis, non-heap protection).
- JVM Heap recommendations (
HeapXms/HeapXmx) are not generated. - Heap environment variables (
CLOUDPILOT_WORKLOAD_AUTOSCALER_JVM_XMS/XMX) are not injected into Pods. - JVM flags (
-Xms/-Xmx,-XX:MaxRAMPercentage, etc.) in container command/args/env are not replaced. - Heap drift detection is skipped — no
JVMHeapDriftin-place fallback will be triggered. - Workload Autoscaler Java UI telemetry may still appear when VM exports JVM metrics, but it is no longer persisted in
status.runtimeInfo.
What Stays the Same
- Runtime language detection still runs — the workload’s
RuntimeLanguagelabel andruntimeProfileare preserved. - CPU recommendations are unaffected (they always use generic percentile calculations).
- All other AP fields (
UpdateSchedule,DriftThresholds,LimitPolicies,ResourceStartupBoost,InPlaceFallback, etc.) continue to work normally.
When to Use
- When a Java workload has its own Heap management (e.g., operator-managed JVM settings) and you do not want CloudPilot AI to modify JVM parameters.
- When you want to use CloudPilot AI purely for container-level resource optimization without JVM-level intervention.